Une autre métrique très utile liée aux tests est la couverture de code. La couverture de code donne une indication sur les parties de votre application qui ont été exécutées pendant les tests. Alors que ce n'est pas en soit une indication suffisante sur la qualité du test (il est facile d'exécuter une application entière sans réellement tester quoique ce soit, et les métriques de couverture de code ne fournissent pas une indication de la qualité ou de l'exactitude de vos tests), c'est une bonne indication du code qui n'a pas été testé. Et, si votre équipe est en train d'adopter des pratiques de test rigoureuses telles que Test-Driven-Development, la couverture de code peut être un bon indicateur sur la façon dont ces pratiques ont été mises en place.
L'analyse de la couverture de code est un traitement consommateur en CPU et mémoire, et va ralentir votre tâche de build de façon significative. Pour cette raison, vous allez généralement exécuter les métriques de couverture de code dans une tâche de build Jenkins séparée, exécutée après que vos tests unitaires et d'intégration aient réussi.
Il y a de nombreux outils de couverture de code disponibles, et plusieurs sont supportés dans Jenkins, tous via des plugins dédiés. Les développeurs Java peuvent choisir entre Cobertura et Emma, deux outils populaires de couverture de code open source, ou Clover, un puissant outil commercial de couverture de code d'Atlassian. Pour les projets .NET, vous pouvez utiliser NCover.
Le fonctionnement et la configuration de tous ces outils sont semblables. Dans cette section, nous allons examiner Cobertura.
Cobertura est un outil de couverture de code open source pour Java et Groovy qui est simple d'utilisation et s'intègre parfaitement à la fois dans Maven et Jenkins.
Comme tous les plugins Jenkins de métriques de qualité de code, [3] le plugin Cobertura pour Jenkins ne va pas lancer les tests de couverture de code pour vous. C'est à vous de générer les informations de couverture de code dans le cadre de votre processus de build automatisé. Jenkins, d'autre part, fournit un excellent travail de rapport sur les métriques de couverture de code, notamment le suivi de la couverture de code dans le temps, et fournissant une couverture de code agrégée sur plusieurs modules applicatifs.
La couverture de code peut être une affaire complexe, et il est
utile de comprendre le traitement que Cobertura effectue, surtout quand
vous devez le mettre en place dans des outils de scripting de plus bas
niveau comme Ant. L'analyse de la couverture de code fonctionne en trois
étapes. D'abord, il modifie (ou “instrumente”) les classes de votre
application, afin qu'elles conservent le nombre de fois que chaque ligne
de code a été exécutée.[4]Il stocke ces informations dans un fichier spécial (Cobertura
utilise un fichier nommé cobertura.ser).
Quand le code de l'application a été instrumenté, vous exécutez vos tests avec le code instrumenté. A la fin des tests, Cobertura aura généré un fichier de données indiquant pour chaque ligne le nombre de fois qu'elle a été exécutée au cours des tests.
Une fois que ce fichier a été généré, Cobertura peut utiliser cette donnée pour générer un rapport dans un format plus lisible, comme XML ou HTML.
Produire des métriques de couverture de code avec Cobertura dans
Maven est relativement simple. Si vous êtes intéressés par la génération
des données de couverture de code, il vous suffit de rajouter le
cobertura-maven-plugin à la section
build de votre fichier pom.xml:
<project>
...
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>cobertura-maven-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<formats>
<format>html</format>
<format>xml</format>
</formats>
</configuration>
</plugin>
...
</plugins>
<build>
...
</project>Cela va générer les métriques de couverture de code quand vous lancerez le plugin Cobertura directement :
$ mvn cobertura:coberturaLes données de couverture de code seront générées dans le
répertoire target/site/cobertura,
dans un fichier nommé coverage.xml.
Cependant, cette approche va instrumenter vos classes et produire les données de couverture de code pour chaque build, ce qui est inefficace. Une meilleure approche est de placer cette configuration dans un profil spécifique, comme montré ici :
<project>
...
<profiles>
<profile>
<id>metrics</id>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>cobertura-maven-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<formats>
<format>html</format>
<format>xml</format>
</formats>
</configuration>
</plugin>
</plugins>
</build>
</profile>
...
</profiles>
</project>Dans ce cas, vous lancerez le plugin Cobertura en utilisant le profil metrics pour générer les données de couverture de code :
$ mvn cobertura:cobertura -PmetricsUne autre approche consiste à inclure les rapports de couverture de code dans vos rapports Maven. Cette approche est beaucoup plus lente et plus consommatrice en mémoire que de générer simplement les données de couverture de code, mais cela peut avoir du sens si vous générez aussi d'autres métriques de qualité de code et leurs rapports en même temps. Si vous voulez le faire avec Maven 2, vous devez aussi inclure le plugin Maven Cobertura plugin dans la section reporting, comme montré ici :
<project>
...
<reporting>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>cobertura-maven-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<formats>
<format>html</format>
<format>xml</format>
</formats>
</configuration>
</plugin>
</plugins>
</reporting>
</project>A présent, les données de couverture de code seront générées quand vous générerez le site Maven pour ce projet :
$ mvn siteSi votre projet Maven contient des modules (comme il est de
pratique courante pour des gros projets Maven), vous devez mettre en
place la configuration Cobertura dans le fichier pom.xml parent. Les métriques de couverture
de code et le rapport seront générés séparément pour chaque module. Si
vous utilisez l'option de configuration aggregate, le plugin Maven Cobertura génèrera
aussi un rapport de plus haut niveau combinant les données de couverture
de code de tous les modules. Cependant, que vous utilisiez cette option
ou non, le plugin Jenkins Cobertura va lire les données de couverture de
code de plusieurs fichiers et les combiner dans un seul rapport
aggrégé.
Au moment de la rédaction, il y a une limitation avec le plugin Maven Cobertura — la couverture de code sera uniquement enregistrée pour les tests exécutés pendant la phase test, et pas les tests exécutés pendant la phase integration-test. Cela peut être un problème si vous utilisez cette phase pour lancer des tests d'intégration ou des tests web qui nécessitent une application complètement packagée et déployée — dans ce cas, la couverture de code des tests qui sont uniquement exécutés pendant la phase integration-test ne sera pas comptée dans les métriques de couverture de code Cobertura.
Intégrer Cobertura dans votre build Ant est un peu plus compliqué que de le faire avec Maven. Cependant, cela vous permet d'avoir un contrôle plus fin sur les classes qui sont instrumentées, et quand la couverture de code est mesurée.
Cobertura est livré avec une tâche Ant que vous pouvez utiliser pour intégrer Cobertura dans vos builds Ant. You devez télécharger la dernière distribution Cobertura, et la décompresser quelque part sur votre disque dur. Afin que votre build soit plus portable, et donc plus facile à déployer dans Jenkins, c'est une bonne idée de placer la distribution Cobertura que vous utilisez dans votre répertoire projet, et de la sauvegarder dans votre système de gestion de version. Ainsi, c'est le moyen le plus facile pour garantir que le build utilisera la même version de Cobertura quelle que soit la façon dont il est exécuté.
En supposant que vous avez téléchargé la dernière installation de
Cobertura et que vous l'avez placée à l'intérieur de votre projet dans
un répertoire nommé tools, vous
pourriez faire quelque chose comme ceci :
<property name="cobertura.dir" value="/jenkins-guide-complet/hudsonbook-content-fr/tools/cobertura" /><path id="cobertura.classpath">
<fileset dir="${cobertura.dir}"> <include name="cobertura.jar" />
<include name="lib/**/*.jar" />
</fileset> </path> <taskdef classpathref="cobertura.classpath" resource="tasks.properties" />
|
|
Indique à Ant où se trouve l'installation de Cobertura. |
|
|
Nous devons mettre en place un classpath que Cobertura utilisera pour s'exécuter. |
|
|
Le chemin contient l'application Cobertura elle-même. |
|
|
Et toutes ses dépendances. |
Ensuite, vous devez instrumenter les classes de l'application. Vous devez faire attention de placer ces classes instrumentées dans un répertoire différent, de telle manière qu'elles ne seront pas déployées en production par accident :
<target name="instrument" depends="init,compile">
|
|
Nous ne pouvons instrumenter les classes de l'application qu'une fois qu'elles ont été compilées. |
|
|
Détruit toutes les données de couverture de code générées par les builds précédents. |
|
|
Détruit toutes les classes précédemment instrumentées. |
|
|
Instrumente les classes de l'application (mais pas les classes
des tests) et les place dans le répertoire |
A ce stade, le répertoire ${instrumented.dir} contient une version
instrumentée de nos classes applicatives. Maintenant, tout ce que nous
devons faire pour générer des données utiles de couverture de code est
d'exécuter nos tests unitaires avec les classes de ce répertoire
:
<target name="test-coverage" depends="instrument">
<junit fork="yes" dir="/jenkins-guide-complet/hudsonbook-content-fr">
<classpath location="${instrumented.dir}" />
<classpath location="${classes.dir}" />
<classpath refid="cobertura.classpath" />
<formatter type="xml" />
<test name="${testcase}" todir="${reports.xml.dir}" if="testcase" />
<batchtest todir="${reports.xml.dir}" unless="testcase">
<fileset dir="${src.dir}">
<include name="**/*Test.java" />
</fileset>
</batchtest>
</junit>
</target>|
|
Exécute les tests JUnit avec les classes instrumentées. |
|
|
Les classes instrumentées utilisent les classes de Cobertura, donc les bibliothèques Cobertura doivent aussi se trouver dans le classpath. |
Cela va produire les données brutes de couverture de code dont nous avons besoin pour produire les rapports XML de couverture que Jenkins peut utiliser. Pour produire ces rapports, nous devons lancer une autre tâche, comme montré ici :
<target name="coverage-report" depends="test-coverage">
<cobertura-report srcdir="${src.dir}" destdir="${coverage.xml.dir}"
format="xml" />
</target>Enfin, n'oubliez pas de faire le ménage une fois que tout est fini : la cible clean ne doit pas détruire uniquement les classes générées, mais aussi les classes générées instrumentées, les données de couverture de code Cobertura, et les rapports Cobertura :
<target name="clean"
description="Remove all files created by the build/test process.">
<delete dir="${classes.dir}" />
<delete dir="${instrumented.dir}" />
<delete dir="${reports.dir}" />
<delete file="cobertura.log" />
<delete file="cobertura.ser" />
</target>Une fois cela fait, vous êtes prêt à intégrer vos rapports de couverture de code dans Jenkins.
Une fois que les données de couverture de code sont générées dans le cadre de votre processus de build, vous pouvez configurer Jenkins pour les afficher. Ceci implique l'installation du plugin Jenkins Cobertura. Nous avons décrit ce processus dans Section 2.8, “Adding Code Coverage and Other Metrics”, mais nous allons le décrire à nouveau pour rafraîchir votre mémoire. Allez sur l'écran Administrer Jenkins, et cliquez sur Gestion des plugins. Cela va vous amener à l'écran du gestionnaire des plugins. Si Cobertura n'a pas été installé, vous trouverez le plugin Cobertura dans l'onglet Disponibles, dans la section Build Reports (voir Figure 6.11, “Installer le plugin Cobertura”). Pour l'installer, cochez simplement la case et appuyez sur Entrée (ou faites défiler jusqu'au bas de l'écran et cliquez sur le bouton “Installer”). Jenkins va télécharger et installer le plugin pour vous. Une fois que le téléchargement est fini, vous devez redémarrer votre serveur Jenkins.
Une fois que vous avez installé le plugin, vous pouvez mettre en place les rapports de couverture de code dans vos tâches de build. Puisque la couverture de code peut être lente et consommatrice en mémoire, vous devrez généralement créer une tâche de build séparée pour cela et les autres métriques de qualité de code, qui sera exécutée après les tests unitaires et d'intégration. Pour de gros projets, vous pouvez même le mettre en place via un build qui s'exécute sur une base quotidienne. En effet, le retour sur les métriques de couverture de code et autres n'est généralement pas aussi critique que le retour sur les résultats de test, et cela va libérer des exécuteurs de build pour des tâches de build qui peuvent bénéficier de retour rapide.
Comme nous le mentionnions précédemment, Jenkins ne fait pas
d'analyse de couverture par lui-même — vous devez configurer votre build
pour produire le fichier Cobertura coverage.xml (ou fichiers) avant que vous
puissiez générer de jolis graphes ou rapports, généralement en utilisant
une des techniques dont nous avons discuté précédemment (voir Figure 6.12, “Votre build de couverture de code doit produire les données de
couverture de code”).

Une fois que vous avez configuré votre build pour produire des données de couverture de code, vous pouvez configurer Cobertura dans la section “Actions à la suite du build” de votre tâche de build. Si vous cochez la case “Publish Cobertura Coverage Report”, vous devriez voir quelque chose comme Figure 6.13, “Configurer les métriques de couverture de code dans Jenkins”.
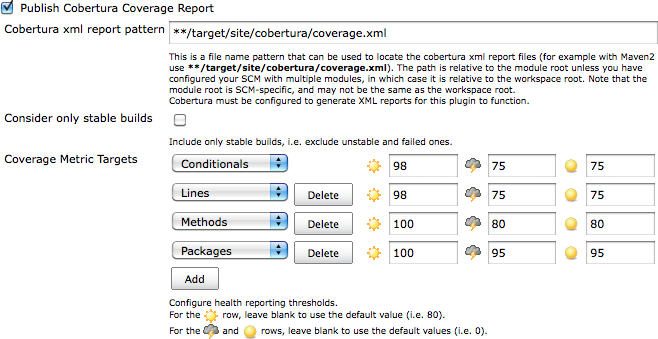
Le premier et plus important champ ici est le chemin des données
XML Cobertura que nous avons générées. Votre projet peut contenir un
seul fichier coverage.xml, ou
plusieurs. Si vous avez un projet Maven multi-modules, par exemple, le
plugin Maven Cobertura va générer un fichier coverage.xml distinct pour chaque
module.
Le chemin accepte des caractères génériques du style Ant, et il
est donc facile d'inclure les données de couverture de code à partir de
plusieurs fichiers. Pour tout projet Maven, un chemin tel que **/target/site/cobertura/coverage.xml inclura
toutes les métriques de couverture de code de tous les modules dans le
projet.
Il y a en fait plusieurs types de couverture de code, et il est
parfois utile de les distinguer. La plus intuitive est la couverture de
lignes, qui compte le nombre de fois qu'une ligne donnée est exécutée
pendant les tests automatisés. “Conditional Coverage” (aussi appelé
“Branch Coverage”) prend en compte si les expressions booléennes dans
les instructions if et semblables
sont testées d'une manière qui vérifie tous les résultats possibles
d'une expression conditionnelle. Par exemple, étant donné le fragment de
code suivant:
if (price > 10000) {
managerApprovalRequired = true;
}Pour obtenir une couverture de code complète pour ce code, vous devez l'exécuter deux fois : une fois avec une valeur supérieure à 10,000, une autre avec une valeur inférieure ou égale à 10,000.
D'autres métriques de couverture de code plus basiques incluent les méthodes (combien de méthodes dans l'application ont été exécutées par les tests), classes et packages.
Jenkins vous permet de définir lesquelles de ces métriques vous voulez suivre. Par défaut, le plugin Cobertura enregistre les couvertures conditionnelles, lignes, et méthodes, ce qui est généralement suffisant. Cependant, il est facile de rajouter d'autres métriques de couverture de code si vous pensez que ce peut être utile pour votre équipe.
Le traitement par Jenkins des métriques de couverture de code n'est pas uniquement un affichage passif — Jenkins vous permet de définir comment ces métriques affectent le résultat du build. Vous pouvez définir des valeurs de palier pour les métriques de couverture de code qui affectent à la fois le résultat du build et le rapport météo sur le tableau de bord Jenkins (voir Figure 6.14, “Les résultats des tests de couverture de code contribuent à l'état du projet sur le tableau de bord”). Chaque métrique de couverture de code que vous suivez possède trois valeurs de palier.
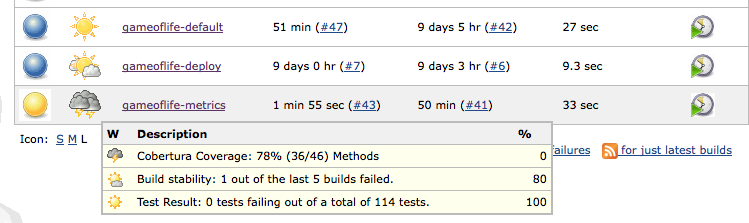
Figure 6.14. Les résultats des tests de couverture de code contribuent à l'état du projet sur le tableau de bord
Le premier (celui avec une icône ensoleillée) est la valeur minimale que le build doit atteindre pour avoir une icône ensoleillée. La seconde indique la valeur en dessous de laquelle le build aura une icône orageuse. Jenkins va extrapoler les valeurs intermédiaires entre ces deux-ci pour d'autres icônes météo plus nuancées.
Le dernier palier est simplement la valeur en dessous de laquelle un build sera marqué comme “instable” — avec une balle jaune. Bien que n'étant pas aussi mauvais qu'une balle rouge (pour un build cassé), une balle jaune entrainera un message de notification et apparaîtra comme mauvais sur le tableau de bord.
Cette fonctionnalité n'est pas un simple détail esthétique — elle fournit un moyen précieux de fixer des objectifs de qualité de code pour vos projets. Bien qu'elle ne puisse pas être interprétée seule, une mauvaise couverture de code n'est généralement pas un bon signe pour un projet. Donc si vous prenez la couverture de code au sérieux, utilisez ces valeurs de palier pour fournir un retour direct quand les choses ne sont pas à la hauteur.
Jenkins affiche vos rapports de couverture de code sur la page d'accueil de la tâche de build. La première fois qu'il est exécuté, il produit un simple graphique à barres (voir Figure 2.30, “Jenkins displays code coverage metrics on the build home page”). A partir du second build, un graphique est affiché, indiquant les différents types de couverture que vous suivez dans le temps (voir Figure 6.15, “Configurer les métriques de couverture de code dans Jenkins”). Dans les deux cas, le graphique affichera aussi les métriques de couverture de code pour le dernier build.
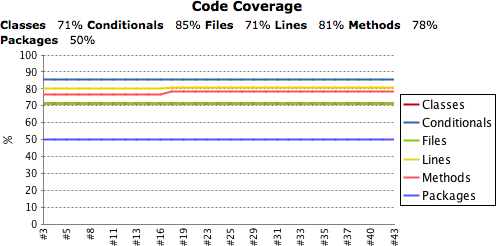
Jenkins offre une grande valeur ajoutée en vous permettant de descendre dans les métriques de couverture de code, affichant les erreurs de couverture de code pour les packages, classes à l'intérieur d'un package, et les lignes de code à l'intérieur d'une classe (voir Figure 6.16, “Afficher les métriques de couverture de code”). Quel que soit le niveau de détail que vous regardiez, Jenkins affichera un graphe en haut de la page montrant la tendance de couverture dans le temps. Plus bas, vous trouverez la répartition par package ou classe.
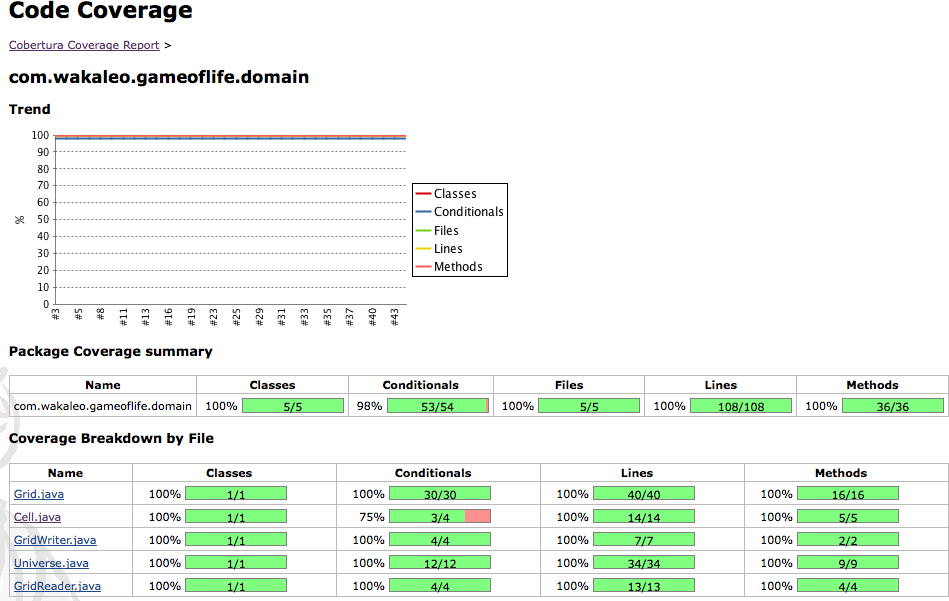
Lorsque vous arrivez au niveau de détail de la classe, Jenkins
affiche aussi le code source de la classe, avec les lignes colorées en
fonction de leur niveau de couverture. Les lignes qui ont été
complètement exécutées pendant les tests sont en vert, et les lignes qui
n'ont jamais été exécutées sont marquées en rouge. Un nombre dans la
marge indique le nombre de fois que la ligne en question a été exécutée.
Enfin, un ombrage jaune dans la marge est utilisée pour indiquée une
couverture conditionnelle insuffisante (par exemple, une instruction
if qui a seulement été testé avec
un résultat).
Clover est un excellent outil de couverture de code commercial d'Atlassian. Clover fonctionne parfaitement pour des projets Ant, Maven, ou même Grails. La configuration et l'utilisation de Clover est bien documentée sur le site web d'Atlassian, donc nous ne regarderons pas ces aspects en détail. Cependant, en guise d'exemple, voici une configuration Maven typique de Clover pour une utilisation avec Jenkins :
<build>
...
<plugins>
...
<plugin>
<groupId>com.atlassian.maven.plugins</groupId>
<artifactId>maven-clover2-plugin</artifactId>
<version>3.0.4</version>
<configuration>
<includesTestSourceRoots>false</includesTestSourceRoots>
<generateXml>true</generateXml>
</configuration>
</plugin>
</plugins>
</build>
...Cela va générer à la fois des rapports de couverture de code HTML et XML, y compris les données agrégées si le projet Maven contient plusieurs modules.
Pour intégrer Clover dans Jenkins, vous devez installer le plugin Jenkins Clover selon la manière habituelle en utilisant l'écran du gestionnaire de plugins. Une fois que vous avez redémarré Jenkins, vous pourrez intégrer les données de couverture de code Clover dans vos builds.
Exécuter Clover sur votre projet est un projet en plusieurs étapes : vous instrumentez votre code applicatif, exécutez les tests, agrégez les données de test (pour les projets Maven à plusieurs modules) et générez les rapports HTML et XML. Puisque cela peut être une operation assez lente, vous allez généralement l'exécuter dans une tâche de build séparée, et pas avec vos test classiques. Vous pouvez le faire comme suit :
$ clover2:setup test clover2:aggregate clover2:clover
Ensuite, vous devez mettre en place les rapports Clover dans Jenkins. Cochez la case Publish Clover Coverage Report pour l'activer. La configuration est similaire à celle de Cobertura — vous devez fournir le chemin du répertoire du rapport HTML Clover, et du fichier rapport XML, et vous pouvez aussi définir des valeurs de palier pour les icônes méteo ensoleillées et orageuses, et pour les builds instables (voir Figure 6.17, “Configurer les rapports Clover dans Jenkins”).

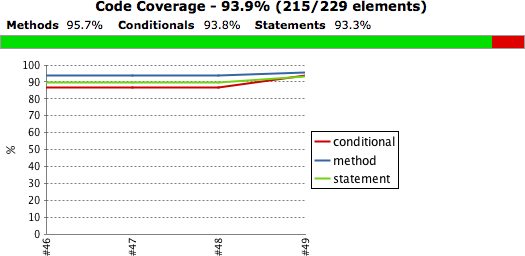
Une fois que vous l'aurez fait, Jenkins affichera le niveau actuel de couverture de code, ainsi qu'un graphe de la couverture de code dans le temps, sur la page d'accueil de votre tâche de build de votre projet (voir Figure 6.18, “Tendance de couverture de code Clover”).
[3] À l'exception notable de Sonar, que nous allons examiner plus tard dans le livre.
[4] C'est en fait une légère simplification ; en fait, Cobertura stocke aussi d'autres informations, telles que le nombre de fois que chaque résultat possible d'un test booléen a été exécuté. Cependant, cela ne modifie pas l'approche générale.